Nima by Tremau is a powerful end-to-end platform to manage every aspect of the moderation process, from automatic and manual screening to ensuring compliance with legal requirements across the globe.
Tremau developers have built an adapter seamlessly linking Tisane to Nima. Beyond the basic functionality, Tremau’s Tisane integration can track conversation context for detection of complex, multistep scenarios like grooming and fraud.
Tisane supports detection of multiple types of problematic content, such as cyberbullying, hate speech, attempts to get users off the platform, allegations, sexual advances, suicidal ideation, spam in reviews, and more. Additionally, Tisane provides standard NLP functions like topics, entity extraction, sentiment analysis, and language identification. Tisane supports 30+ languages, with new languages on the way.
Maltego is a popular data mining, aggregation, and visualization tool, used in OSINT, investigations, and other applications. Maltego team has built a connector (a module called “transform” in Maltego) seamlessly linking Tisane. Maltego users can now combine the power of Tisane with other data sources and applications.
Make (formerly Integromat) is a visual platform that lets you design, build, and automate anything – from simple tasks to complex workflows – in minutes.
Tisane is now published in Make App & Services Directory. You can now mash Tisane with thousands of apps and services supported by Make.
Tisane Bot for Slack is an easy to use moderation aid for Slack communities great and small. Monitor your Slack channels for cyberbullying, insults, data leaks, hate speech, and other HR policy violations. The bot is easy to install and does not require IT expertise.
Tisane Bot comes with all the capabilities Tisane API has to offer:
30 languages are supported
detailed explanation why the post was flagged
reduces moderator chores by 95%
for non-English posts, automatic translation is provided
Darjeeling is the name of our 2021 Tisane update. While we worked on multiple parts of the system, the focus in this update is on moving beyond the “sliding window” of one sentence. The current edition adds powerful tools to make the system aware of non-textual content, as well as context coming from different messages.
See below short notes on the new features and changes.
Automatic Language Detection
For those working with multiple languages, it is now possible to use the automatic language detection. In addition to the new method, it can be activated in other methods as well; simply specify * as the language code value. If the likely languages are known, specify them the vertical bar-delimited list of the likely language codes, e.g. en|es|ja.
More Subtypes for Abuse
We added more tags to describe the various shades of abuse. In the instances of hate speech (bigotry type), we now detect the protected class being targeted, generating tags like racism, xenophobia, sexism, religion, and more.
Runtime Redefinition: Codewords & More
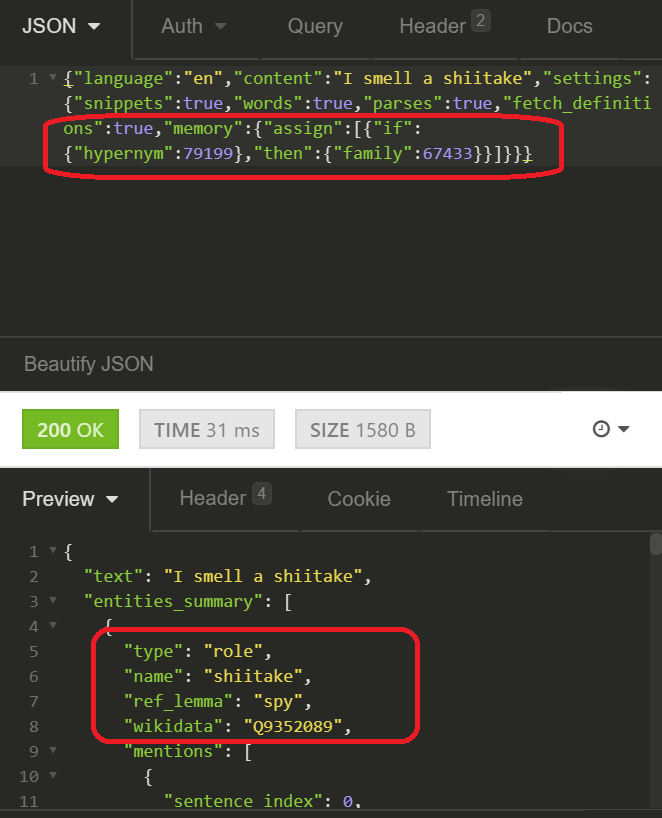
Redefining concepts & features on the fly became possible thanks to the brand new Long-Term Memory module. From conversations with the law enforcement users, we learned that codewords are a persistent challenge that subverts detection efforts. Tisane now allows redefining what concepts mean; not just adding word for word, but redefining entire families or even categories.
E.g. if someone consistently means spies when mentioning any types of mushrooms (be it champignons, chanterelles, etc.), there is a new structure in the settings that allows redefining it. Upon learning of the hidden meanings, the users then can request the service to interpret some concepts differently, reprocess the text, and detect patterns that were skipped. Contact us to learn more.
The redefinition module allows redefining both meanings and features. For example, we can define that the gender of the speaker or the interlocutor for languages where these pronouns do not have gender, generating translations with the correct gender. We can assign new categories, reflecting subjective opinions (e.g. link a particular political faction to the concept of “unwelcome person” to gauge sentiment). The runtime redefinitions will then work in concert with the pre-built language models.
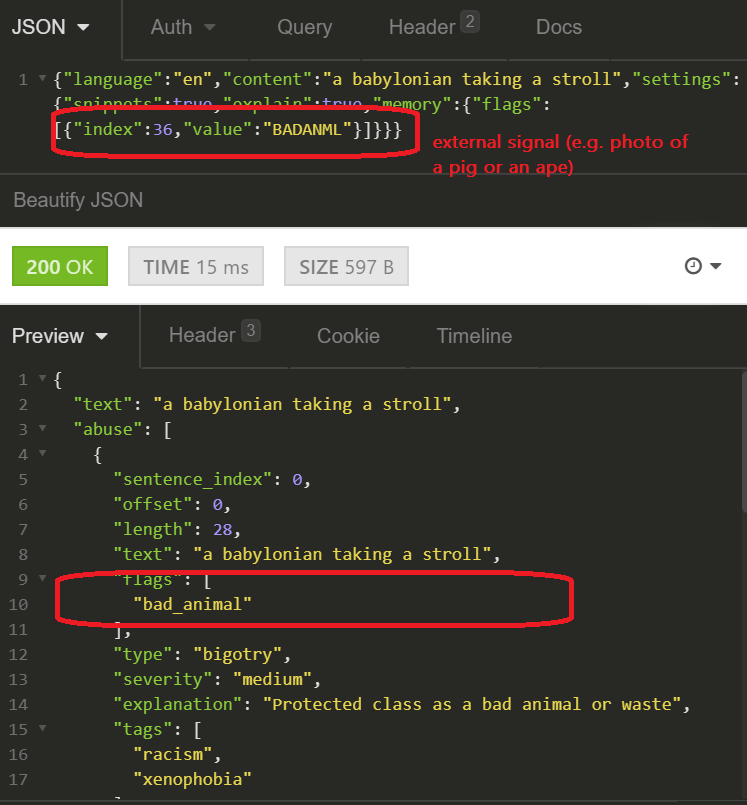
Nontextual Context Flags
Another use of the Long-Term Memory module is to define non-textual context. For example, if a meme shows a pile of refuse or an animal associated with negative qualities (ape, pig, snake) and the text overlay names a protected class, the text in itself is not offensive. However, the message is undoubtedly is. It is now possible to set a flag for particular types of situations. These flags will provide context, allowing Tisane to detect more.
Multi-step Detection
For the subtle and gradual kind of abuse, the picture is never clear from just one sentence. The offender may require multiple steps to gain confidence of the victim, or spin a long story, each part of which is neutral in isolation.
We now allow issuing alerts only when several flags fire. While Tisane remains stateless, it is possible to port the context and the accumulated knowledge from the previous messages in the conversation to the subsequent messages.
Our partners at Quickwork, a platform that allows building any workflow automation in minutes, integrated Tisane API .
Tisane can now be linked to thousands of applications and APIs using Quickwork’s simple and powerful UI, no coding skills required. For example, use Quickwork’s moderation plug-in for Slack using Tisane. See the video of the Slack plug-in in action here.
Quickwork is an enterprise-grade, ISO 27001 and GDPR compliant, no code, API-based, SaaS platform with an extensive range of pre-integrated business- and consumer- apps to solve various automation problems. It offers three key capabilities – Integration, API Management & Conversation Management as a Service. This platform’s Real-time messaging & API based architecture makes it easier to build on these capabilities to offer better workflow solutions and customer experience.
SINGAPORE, Oct. 13, 2020 /PRNewswire/ — Tisane Labs, a supplier of text analytics AI solutions, today announced a new feature in Tisane API, already available on Microsoft Azure Marketplace and AppSource. With the new feature, Tisane API now allows tagging and extraction of Wikidata entities, complementing the capabilities provided by Azure Cognitive Services and supporting nearly 30 languages.
“Wikidata allows utilizing Wikipedia knowledge in ways never explored before, but there’re not many ways to get Wikidata references from unstructured text,” said Vadim Berman”Now, with the new feature of Tisane API built on Azure, our users can easily obtain Wikidata IDs from Tisane’s JSON response. Imagine being able to annotate text with images, GPS coordinates, important dates, 3rd party references, and whatever the ever-growing and open Wikidata database contains.”
“Microsoft Azure Marketplace and AppSource lets customers worldwide discover, try, and deploy software solutions that are certified and optimized to run on Azure,” said Sajan Parihar, Senior Director, Microsoft Azure Platform at Microsoft Corp. “Azure Marketplace and AppSource helps solutions like Tisane API reach more customers and markets.”
Tisane API runs in the cloud utilizing Azure API Management, with a simple REST interface that can be linked from any popular programming platform today. Tisane Labs provides a range of tailored plans for its clients with the option of a custom installation on-premises and a free plan.
The next update after Boldo has to start with C, and so it’s Chai this time (no, corona does not qualify).
It has been a busy year. With more users and new use cases come more feature requests, and we worked hard to implement them.
Explainability
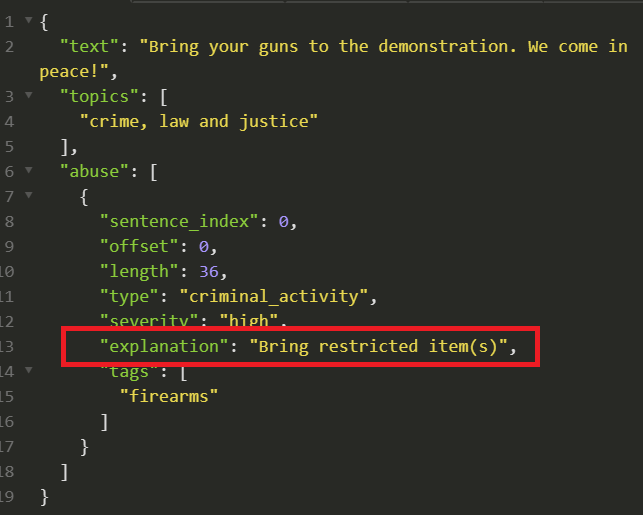
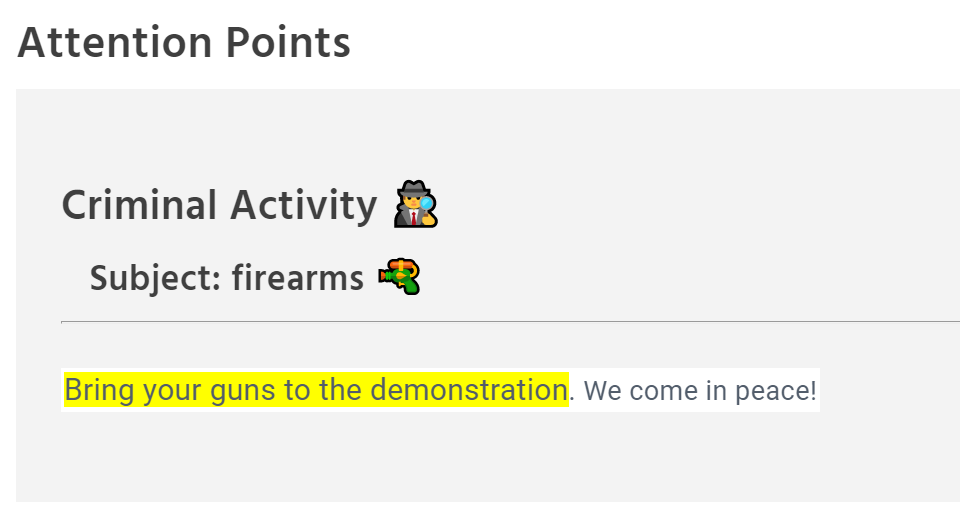
In the moderation space, it helps to provide a cue why the system classified a message as problematic. Human moderators are often stressed, overworked, and overwhelmed, while natural language processing is bound not to be 100% error-free. Reducing their task to a simple “sanity check” whether the system understood the utterance makes them more productive and more consistent. When the explain setting is set to true, Tisane provides a short snippet describing the reasoning (settings: read more here).
JSON response including an explanation
Pinpointing problematic content
Name Parsing & Validation
Many communities require users to enter real names. Some users prefer not to, for different reasons. In some cases, there is a need to break down a full name into constituents, such as given name, surname, middle name, etc.
Tisane now provides methods to:
parse names into constituents, extracting the components
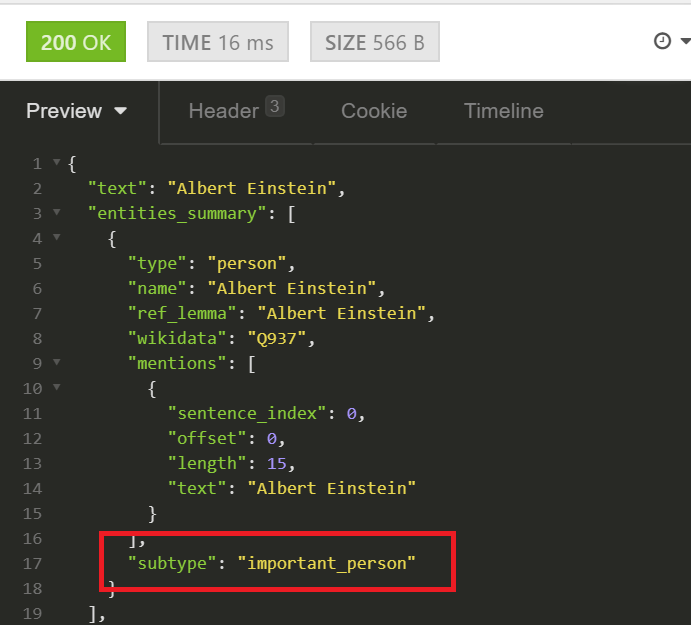
validate names, tagging names of important people, spiritual beings, and fictional characters. No more Boba Fett or Satan as a real name!
compare names in the same or different languages, producing a list of differences
JSON response recognizing a name as that of an “important person”
Wikidata IDs are now supported at the level of entities, topics, and even some non-entity words.
Imagine deducing geographic coordinates, Britannica article ID, or semantic properties from text that went through Tisane!
New Formats, Entity Types, Abuse Types
Different content formats may have different logic tied to them, especially when the context is lacking. With new requirements, we added two new formats:
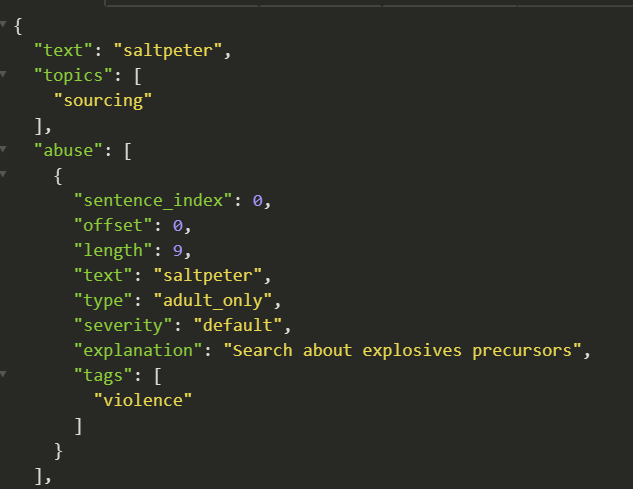
search to screen search queries
alias to screen user names in online communities
Example of search query screening
With more law enforcement vendors adopting Tisane, we were asked to add entity types of interest to the law enforcement, specifically:
weight
bank_account
credit_card, including subtypes representing the major credit card types