
Introduction
NLP has its own unique challenges in law enforcement & intelligence scenarios. These challenges are rarely addressed by the mainstream NLP frameworks. From the conversations with our law enforcement users, we learned that the use of code words subverting detection efforts is one such challenge.
Oftentimes, offenders or intelligence assets replace important words by seemingly unrelated mutually agreed upon terms. You never know who’s listening, right? Or where the device ends up. Code words are not the same as jargon or slang; it’s a disposable secret language designed to obscure the real meaning.
Once the investigators start guessing what these unrelated terms mean, they can try using keywords. But what if it’s more than a couple of words, or the inventors are particularly creative or supplement it with purportedly introduced misspellings?
What if the misspellings are the auto-correct gone rogue?
Tisane has a solution for that.
Peeking Under the Hood
In Tisane, text processing is built around concepts (or word-senses) rather than words. The word-senses are clustered in structures called families, each provided with a unique numeric ID. A family contains a set of synonyms and their inflected forms, complete with a set of features. The family ID is crosslingual, as clusters of synonyms are aligned across all languages supported by Tisane, now or in the future.
By default, Tisane’s decisions are made based on the data coming from its language models. However, since the Darjeeling release, Tisane has a so-called “long-term memory” module. The long-term memory module, among other things, allows making changes to attributes at the level of a call, “redefining” the contents of memory, and preserving the accumulated knowledge, if the calling application chooses to do so. As the word-sense is just one of the attributes, it can be redefined on the fly, too. Doing so assigns a new sense to whole categories. As the family IDs are crosslingual, there is no “family ID for English” or “family ID for Japanese”. It’s exactly the same family ID everywhere.
To assign a new meaning to the code words, the settings parameter in Tisane’s processing methods (POST /parse and POST /transform) must contain the section where the redefinition takes place. The concepts matching the redefinition criteria are then assigned the new attributes. To redefine the word sense, we simply need to supply a new family ID.
In your application, you may allow your users to look up and redefine the word sense on the spot, in order to run experiments with information extraction.
Examples
Mushrooms as Code Words for “Spy”
Let’s say, a group agrees among themselves that when they will mention a mushroom (of any kind), they will actually mean a spy. It may be a chanterelle, a truffle, or any other type of mushrooms.
We’ll use two methods:
- GET /lm/senses (in Tisane Embedded, ListSenses) to locate the family IDs for the relevant concepts.
- the same old POST /parse (in Tisane Embedded, Parse), for which we’ll need to build a redefinition clause.
In Tisane, we need to:
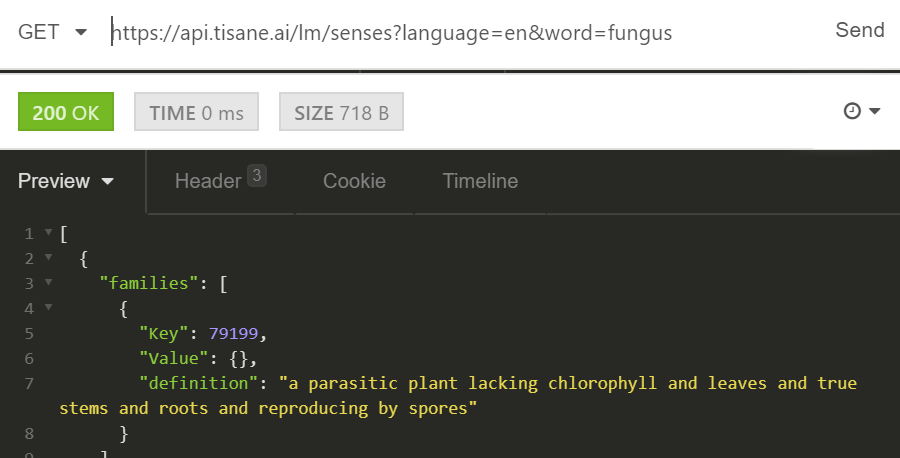
- Look up the family ID of fungus. This is accomplished by invoking GET /lm/senses as shown on the screenshot below. Our family ID is stored in the Key attribute, it is 79199. This is the family that will be used for our criteria. (In cases when there are several interpretations, find the correct one from the definition.)
2. Look up the family ID of spy. Again, this is accomplished by invoking GET /lm/senses as shown on the screenshot below:
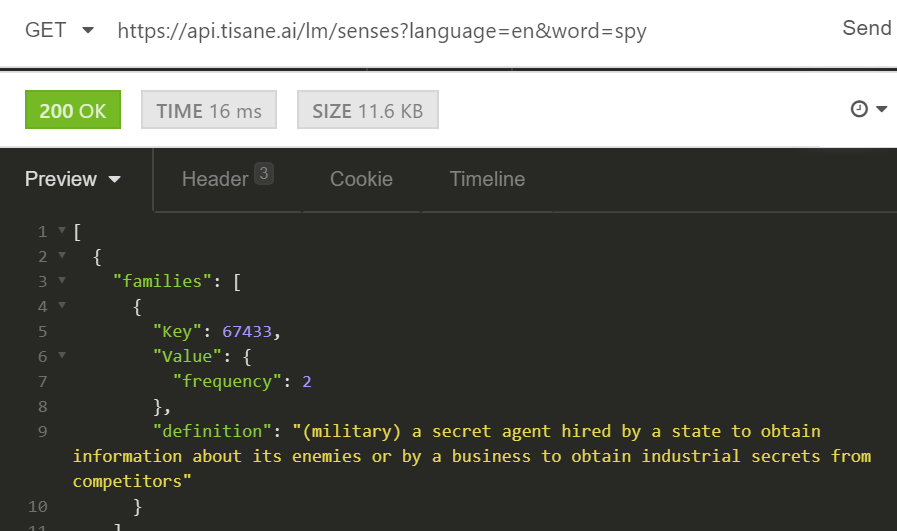
There is a number of senses; looking at the definition attribute, we see that there is one sense that means a “secret agent”. The family ID is 67433. This will be our target family.
3. Finally, we can build our reassignment clause. We want any kind of fungus to match.
Meaning, we need to match all word-senses whose hypernym (an umbrella concept or a super-family, if you will) is fungus (79199), and redefine them as a family 67433 (spy). The reassignment clause is:
{"if":{"hypernym":79199},"then":{"family":67433}}
The reassignment clauses are kept in the assign array under memory.
Let’s test:
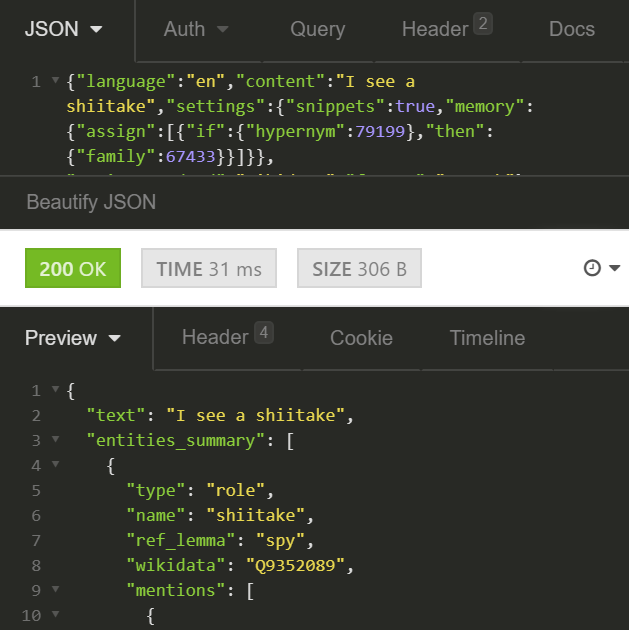
Finding Items Used in Criminal Activities
Suppose a law enforcement agency is looking to locate any record of items that could have been used in a burglary. We can, of course, manually search for hammers, screwdrivers, maybe other tools. We may find something or miss something.
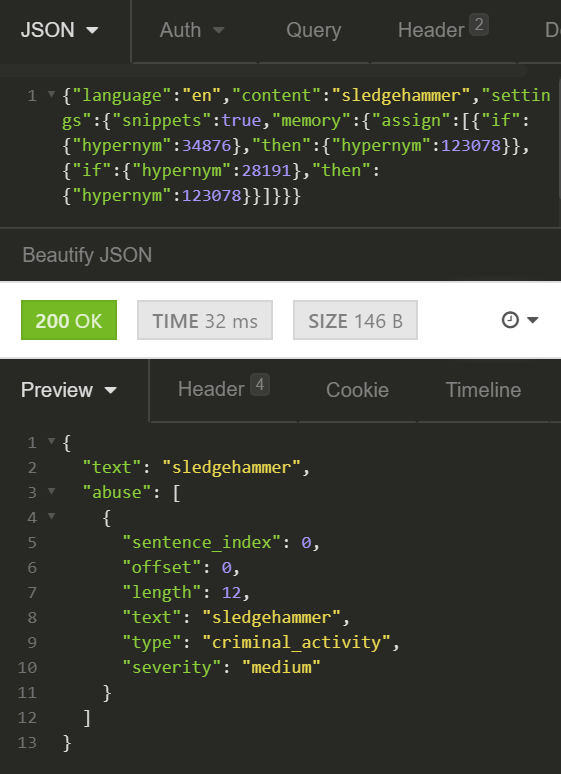
We can, on the other hand, link all the tools (e.g. hammers, drills, etc.) and fasteners (e.g. nails) to the category of “illegal item”. That does not mean that the item is illegal, of course, but it will cause Tisane to generate a criminal_activity alert.
We need to:
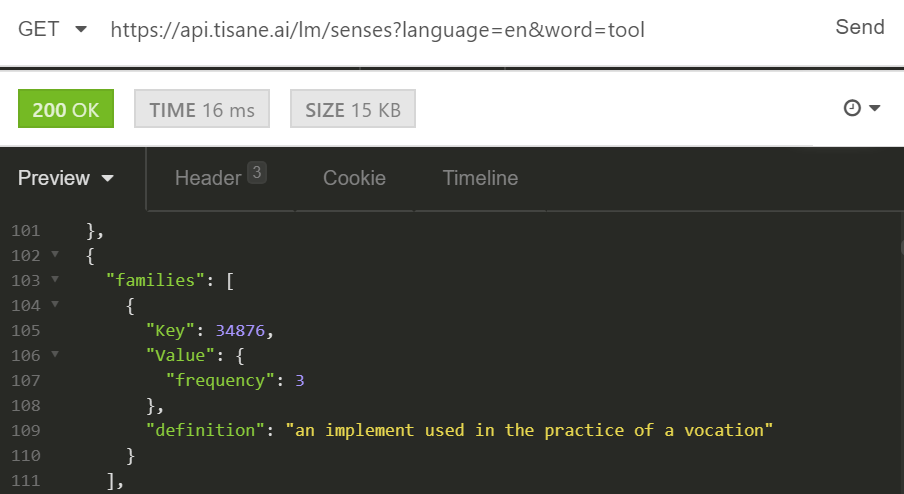
- Look up the family ID of tool and fastener. The family IDs are 34876 and 28191, as can be seen from the screenshots below:
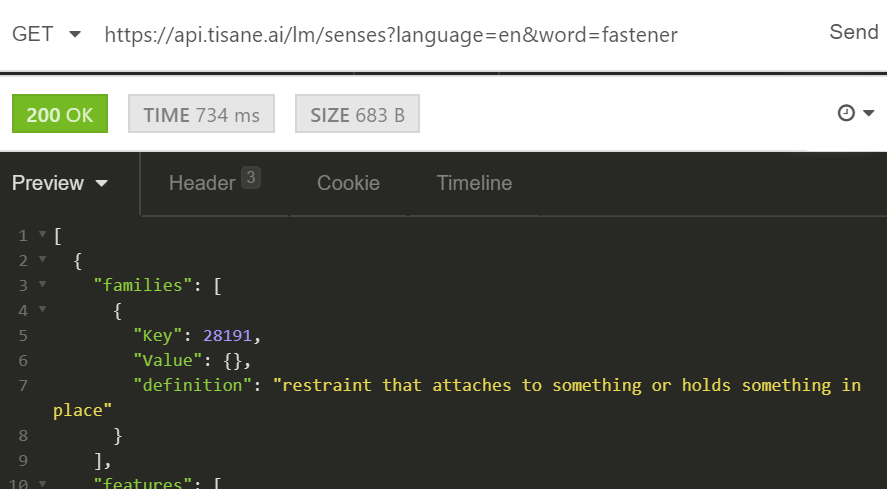
2. Look up the family ID of illegal item. The family is 123078.
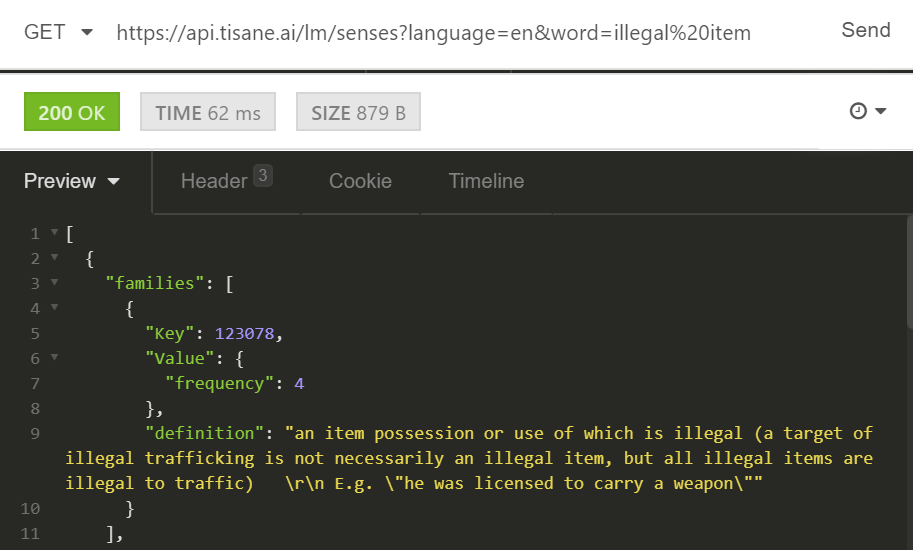
3. Build the reassignment clause. We want items that have family ID 34876 as a hypernym, and those with 28191 as a hypernym, to be linked to hypernym 123078. That will still leave their existing hierarchy intact (they will still be “tools” and “fasteners”), but will have a new link. The assignment array is:
[{"if":{"hypernym":34876},"then":{"hypernym":123078}},
{"if":{"hypernym":28191},"then":{"hypernym":123078}}]
Let’s test:
Linking Names of Discussion Participants
Many of Tisane’s patterns marking personal attacks are looking for discussion participants. The trouble is, with a name alone, it’s impossible to know whether they are participants in the current discussion. On the other hand, the names and the aliases could be available from other sources.
Wouldn’t it be handy if there was a way to tell Tisane that Kewldude1995 and John_Smith are names of the participants, and the attacks on them should be treated as personal attacks?
While it may not be a “code word” problem, the solution is exactly the same: redefining family IDs. This time, based on a string pattern (as these names are not mapped in the language models).
We need to:
- Look up the family ID of discussion participant, as shown on the screenshot below:
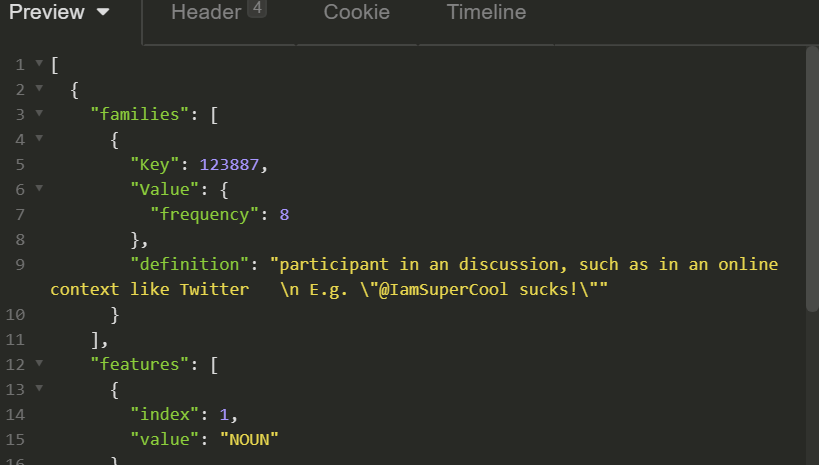
2. Unlike in the previous examples, we need to rely on plain string recognition. This is done by defining a regex condition:
{"if":{"regex":"Kewldude1995|John_Smith"},"then":{"hypernym":123887}}
Let’s test:
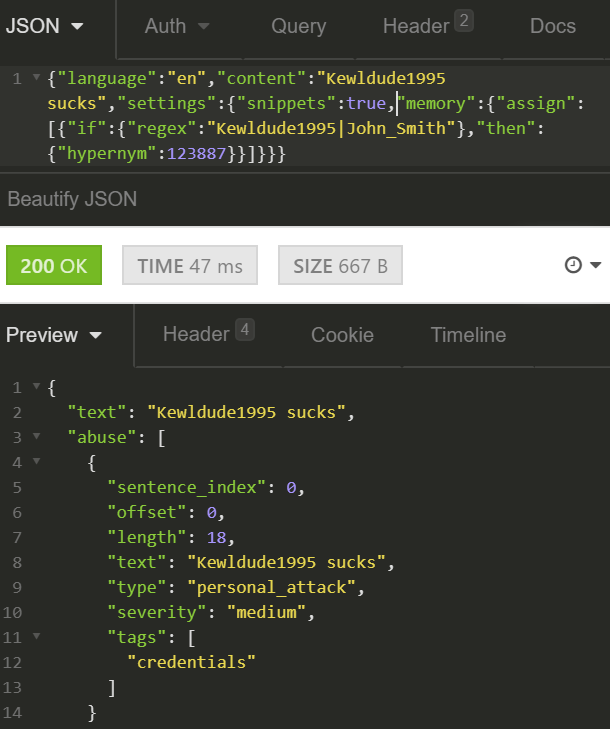
What if we want to treat all names as discussion participants? Then the condition in the second step is to be replaced by a condition looking for a name:
{"if":{"hypernym":44155},"then":{"hypernym":123887}}
Conclusion
In this post, we’ve shown how to use Tisane to extract information while redefining the language models on the fly. These techniques can be used to tackle challenges like secret language and auto-correct.
If you have any questions, or remarks, please feel free to contact us or connect to us on LinkedIn.
In the next posts, we’ll show how to use the same long-term memory module to detect patterns based on multiple signals, tackling challenges common in applications like detection of child grooming and fraud.