Tisane API now provides built-in spellchecking, as well as hashtag parsing capabilities. Just like with all the other functions, the functionality is supported across all the languages.
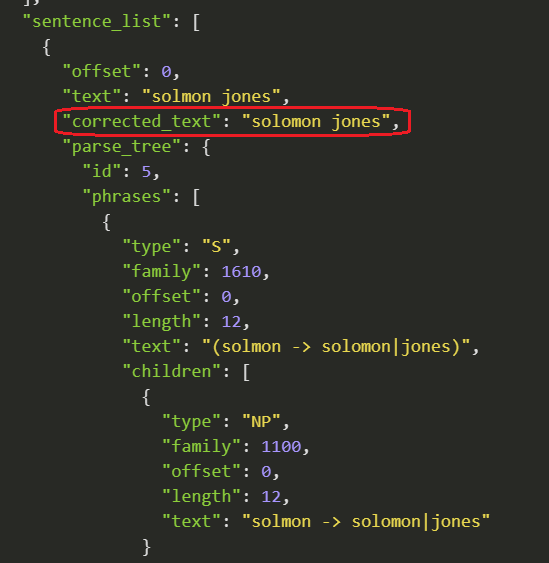
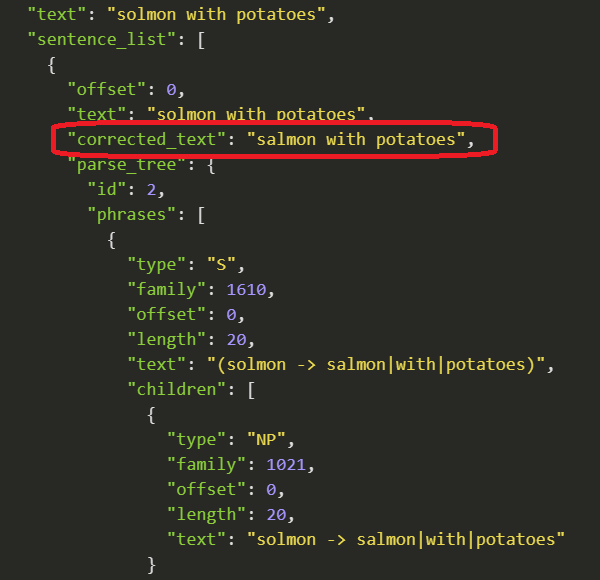
The spellchecking is context-sensitive; for example, as shown on the screenshots below, solmon may be interpreted either as Solomon or salmon, depending on the context.
Note that we do not provide full contextual spellchecking, when the word is legitimate (for example, they’re vs their, or you’re vs your). The spellchecking is also not supported for the languages not using the white space, such as all flavours of Chinese, Japanese, or Thai. Tisane also skips special entities, such as email addresses, phone numbers, online aliases, and names.
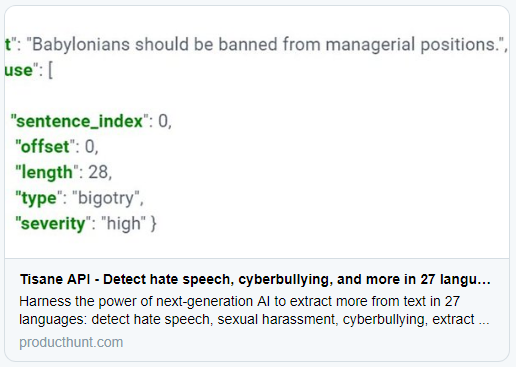
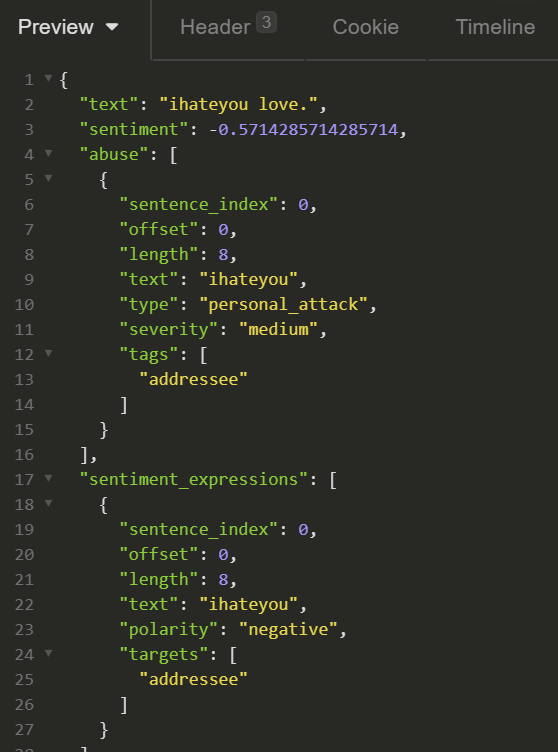
As Tisane API is aimed at abuse detection, the jargon, as well misspelled and/or obfuscated swearwords, is supported.
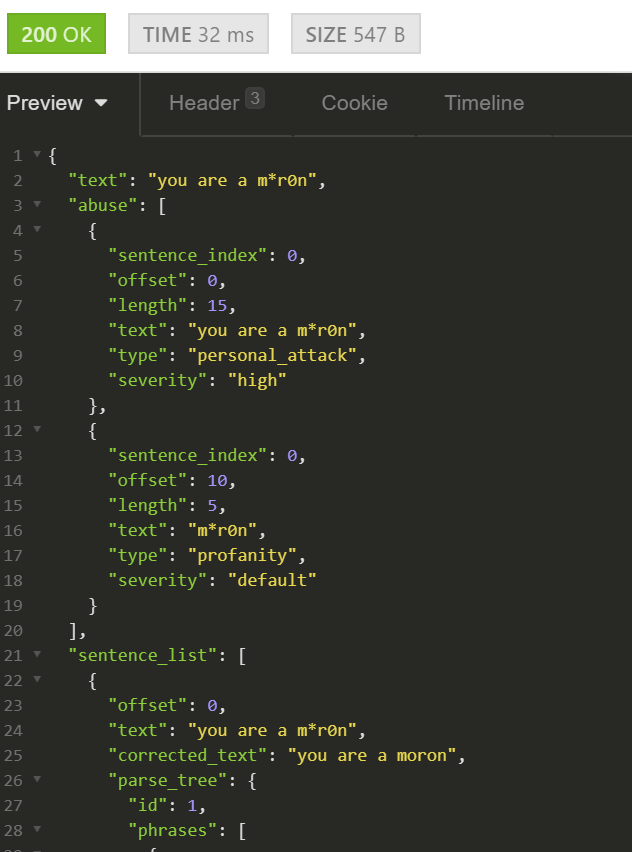
The spellchecking can be used to detect and correct obfuscated swearwords, as shown on the screenshot below:
The spellchecking / deobfuscating functionality is part of the /parse method. To disable the spellchecking, set the disable_spellcheck setting to true:
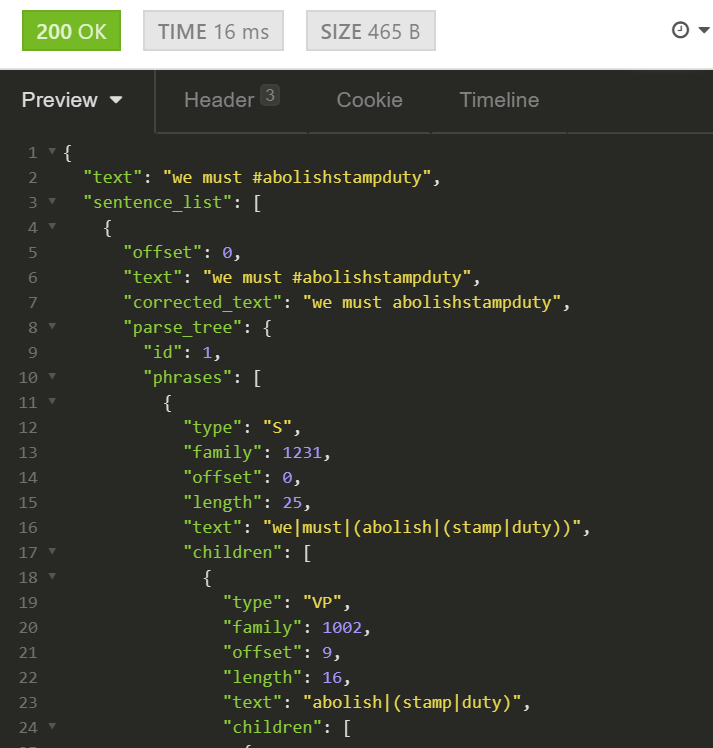
The hashtags can now be parsed, whether they contain cues like underscores or camel case, or not, and integrated with the rest of the utterance, as shown on the screenshot below:
The same functionality is used (in a limited scope) to de-obfuscate utterances spelled without spaces, like in the screenshot below:
The spellchecking / deobfuscating functionality is part of the /parse method.
WARNING: the hashtag parsing is off by default. It is activated by the subscope parameter in the settings:
...
"settings": {"subscope": true}
...
Do not hesitate to contact us for questions and more information. If you are new to Tisane, please sign up here, it’s free up to 50,000 requests a month.
Tisane API can be now used to moderate chat messages in Zendesk’s Smooch platform.
Zendesk is a world leader in customer service software. Smooch is a conversational platform that collates messages across web, mobile, and social messaging and combines user activity and existing profile data, enabling admins to create more tailored experiences. A hotel, for instance, could give guests the ability to ping staff on-property, and an online retailer could manage issues like incorrect shipments and returns across channels.
With support of Tisane, Zendesk users can:
Tag and classify abusive content, like profane and non-profane insults, hate speech, sexual harassment, criminal activity.
Track and tag attempts to establish external contacts between the users.
Extract topics, entities, and more.
The Tisane integration is aimed at:
Online communities looking to improve and streamline their moderation process.
Business chat operators trying to block abusive, hostile and irrelevant content.
Enterprises trying to keep the online conversations compliant with HR regulations and abuse-free.
e-Commerce portals that need to track and/or prevent deals bypassing them.
We’re hosting a demo at the upcoming Interpol World next week here in Singapore. Our session is part of the Global Meeting on AI for Law Enforcement, organised by UNICRI and Interpol, Track 3, Group 2, between 1:30pm and 4pm. If you can’t make it to our session but would like to talk, please contact Vadim Berman or Cheng Zuo.
Following the requests of our users, we implemented additional features. They are now active; feel free to kick the tires. (And yes, our updates are named after herbal teas.)
Detecting Attempts to Establish External Contact
In some communities, external contacts must be monitored. Marketplaces, communities with some kind of harassment issues, scammers attempting to lure users out, and so on. As of today, a common simple solution is to scan messages using regular expressions and find phone numbers and emails. That, however, is insufficient, as the users often find ways to bypass these checks, or introduce non-standard formatting.
We now detect these attempts and place the detected snippets with the external_contact type. For example, a request to provide an email, a WhatsApp number, and so on (“we need your email”, “wat is ur whats app”, etc.).
Signal to Noise Ranking
If you need to create a summary or write a report about how a particular topic or brand is reflected in the social media, the sheer amount of posts that need to be processed is often overwhelming. What’s worse, 95% of these are not much help. They either copy other people’s thoughts, are completely off-topic, contain all kinds of abuse, or just vent frustration and negative emotions. Same goes for the comments: with a few pearls, many are just background noise.
The signal to noise ratio is not unlike conventional search engine rankings, but better adapted for the social media content needs.
The ranking prioritises posts related to the specified concepts and domains, and penalises off-topic content and abuse.
In order to compute the signal to noise ranking, provide an array of concept IDs (family IDs) in your settings under the relevant attribute (e.g. “relevant”: [12345,6789]).
Native Topic Standard Overhaul
While we support taxonomy standards like IPTC and IAB, our internal taxonomy is much richer. The topics that don’t appear in IPTC and IAB can be exposed using the native topic mode (code: native). Previously, it was used for internal purposes only, and contained numeric codes.
After this update, they contain English descriptions, and the taxonomy was also expanded.
Topic Optimization
Some of the topics may overlap. “Compound” topics like cryptocurrency may imply other topics like finance and software. Depending on your application, you may or may not need these “constituent” topics.
The optimize_topics parameter allows control over how it’s presented. For example, when analyzing a sentence like “exchange btc to xmr”, and the optimize_topics is set to false, we get:
We had to learn the hard way that it matters where the text is coming from.
A simple example. A single word like “fool” may be a title, in which case it bears a negative connotation, but not a personal attack. However, when posted as a part of a dialogue (e.g. in a comment in Instagram), it is a personal attack.
We introduced support of different logic for different formats.
Feature Default Format Changed to Universal Dependencies
Tisane supports several standards to display grammar features, such as Penn, Universal Dependencies, Glossing Abbreviations, and the native codes and descriptions. We saw that the original glossing abbreviation format was confusing for many users, and changed the default to Universal Dependencies.
If you prefer to do so, you can still use “glossing” to obtain glossing abbreviations.
Document-Level Sentiment
While we stress that the aspect-based sentiment analysis provides more actionable intelligence, we added a document-level attribute for certain scenarios. Add “document_sentiment”:true to the settings to obtain the document-level sentiment value in range -1 (most negative) thru 1 (most positive). It will be placed in the sentiment attribute.
Contact us for questions and more information. If you are new to Tisane, please sign up here, it’s free.
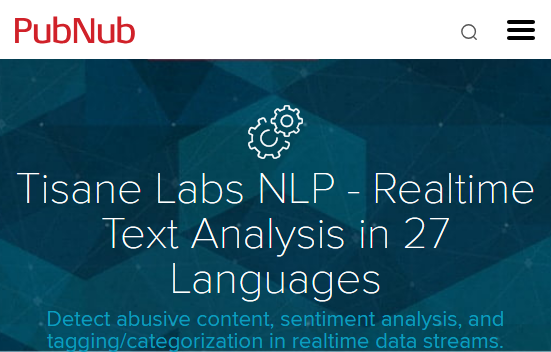
PubNub, the company behind the world’s leading realtime Data Stream Network (DSN), added Tisane API as a supported component in its catalog. The Tisane Labs Natural Language Processing Block runs serverlessly in the PubNub network, joining the blocks released by Microsoft, Amazon, IBM, ESRI, and more. The block fully supports the original Tisane functionality, including:
Detection of personal attacks and cyberbullying, hate speech, criminal activities, sexual harassment
Topic modelling, compliant with IPTC and IAB standards
Sentiment analysis 2.0
Entity extraction
And more.
The PubNub Data Stream Network powers thousands of apps, streaming 1.9 Trillion messages to over 330 million devices a month, with powerful and extensible frameworks like PubNub ChatEngine™ .
Affordable API enables developers and businesses to detect hate speech, cyberbullying, unwanted sexual advances, criminal activity, and more
WASHINGTON, Nov. 13, 2018 /PRNewswire/ — Tisane Labs, a supplier of text analytics AI solutions, today announced the launch of Tisane API, the first API to detect and classify abusive textual content in 27 languages. Tisane detects hate speech, personal attacks, unwanted sexual advances, and criminal activity in text, with additional varieties of detected abuse to come.
“Trolls, bigots, harassers, and criminals made the Internet an unpleasant and at times dangerous place. For the users, it often means being unsafe online with possible consequences in real life. For the online communities, it means high user turnover, additional headaches with the moderation, and enormous monetary losses or legal issues,” said Vadim Berman, Chief Executive Officer and Co-founder of Tisane Labs. “Now, with Tisane API, the communities online can automate much of the moderation process and even warn potential offenders before the post is published. Rather than producing a blanket statement and a floating-point figure, Tisane API pinpoints the actual instance of abuse and classifies the type of abuse.”
Tisane API runs in the cloud, with a simple REST interface that can be linked from any popular programming platform today. Tisane Labs provides a range of plans for every pocket with the option of a custom installation on premises and a generous FREE plan.
We welcome Carla Johnston, who was also a part of the former LinguaSys team, onboard as our Chief Revenue Officer. Carla brings a wealth of knowledge and experience in the natural language processing sales and enormous dedication. Carla is located in the Washington D.C. area.
Tisane Labs is pleased to announce the release of Tisane API.
Harness the power of next-generation AI to extract more from text in 27 languages: detect hate speech, sexual harassment, cyberbullying, extract topics, and find not only whether, but also why the customer is happy or unhappy with your product or service. Our applications and components are accessible in the cloud on a subscription basis (SaaS), can be installed on premises, or embedded in 3rd party applications for seamless integration and security.
We offer several ways to use our components, from a generous free plan (not a limited trial) to enterprise-grade plans and on prem installation options. Whether you’re a small startup, an independent developer, or an enterprise, we can work together.
Questions? Browse our knowledge base, chat with us using the real-time chat widget, or email us.



 We welcome Carla Johnston, who was also a part of the former LinguaSys team, onboard as our Chief Revenue Officer. Carla brings a wealth of knowledge and experience in the natural language processing sales and enormous dedication. Carla is located in the Washington D.C. area.
We welcome Carla Johnston, who was also a part of the former LinguaSys team, onboard as our Chief Revenue Officer. Carla brings a wealth of knowledge and experience in the natural language processing sales and enormous dedication. Carla is located in the Washington D.C. area.