For the International Mother Language Day 2019, 21st February, we interviewed Tisane Labs CEO, Vadim Berman.
Q: Vadim, you are a co-founder and the CEO of Tisane Labs, that provides text analytics for over 20 languages. How did you get involved with languages?
Vadim Berman, CEO, Tisane Labs
VB: One could describe me as a “serial immigrant” or “ethnically confused” 😊. I lived in 6 countries; my first move happened back in 1991 from then-Soviet Union to Israel, when I was in my teens. I had to master Hebrew at school; I was also the family translator. I was upset about the fact that my English, which I thought was pretty good, was nowhere near the local level. I sat with a textbook and then forced myself to manage a diary in English.
Later, when I started my career as a software engineer, I became obsessed with tying between languages and software. The first push to explore the world of natural language processing was an article in Wired back in 2000 called Talking to Strangers. (Looks like it’s still there: https://www.wired.com/2000/05/translation-2/ – little did I know that I would meet some of the people mentioned there in person.) The second push was a speculative fiction story by Jorge Luis Borges called Tlön, Uqbar, Orbis Tertius, which describes an imaginary world whose inhabitants deny reality, and as a result, use languages without nouns. I was wondering how software could handle this kind of language.
I had zillions of ideas and wanted to try them all. I thought the combination of my linguistic and software development skills gives me an advantage. I started experimenting with machine translation and extraction of meaning. The interest became an obsession, the obsession then became a living, and in a few years, already living in Australia, I cofounded LinguaSys, an American venture which was later acquired by Aspect Software, a US-based multinational. I met much of my current team in LinguaSys. I went on to start Tisane Labs in 2017, after I left Aspect.
Q: Tisane stands apart supporting so many different languages. Can you explain why?
VB: In one colloquial sentence, because we can and because we have to.
The decision to focus on multilingualism was both motivated by the economics and the possible applications. There is a shared linguistically neutral core, and so a new language is not started from zero. There are multiple devices to easily reuse shared elements between language models.
When the less mainstream languages take less effort to add, they become more economically viable. As these markets are often underserved, we can benefit from less competition and more coverage.
While there are many use cases when one or two languages are enough, in many scenarios like hospitality industry, no matter how small your business is, ignoring most languages means ignoring a significant segment of your customer base.
Q: Can you give us some interesting examples of something similar / different among these languages?
VB: Funny enough, the biggest similarity is that in every language, many native speakers believe that their language is the most unique, the most complex, and deserves the most special treatment.
My focus is on the inner workings of languages. I see them not as an amorphous bag of words, but as a set of cogs, levers, and pulleys.
On the structural level, after a while it looks like different languages borrow from more or less the same bag of tricks. There are lots of differences, of course, but when we add support to a new language, we find that a new phenomenon can be handled the same way as a seemingly different phenomenon in a different language. For example, when you think of it, English compound verbs (like “give away” or “tell off”) behave somewhat similarly to the German and Dutch separable verbs (e.g. “ankommen” in German), and so the ways we handled both are very similar.
All in all, languages are influenced by the national mindset. If the speakers see a need for a word or a structure, it will be invented. If they like nuance, one word will have less interpretations. At one point, my team was working with hotel and restaurant reviews, which are a pretty good representation of how an average person thinks. We had a blast looking at all the different aspects. There were lots of Swedish reviews for some reason obsessed with glass doors in the bathroom. Russians were keen to write long, creative travelogues. My personal favourite was a French review of a fine dining establishment, which was ending with the following, “It was almost perfect. Almost! The tiny flaw we found was that the antenna of the lobster was broken. All the rest was wonderful, and I would’ve given 9.5 out of 10, but because there is no way to deduct a fraction of a point, I give 9 out of 10.”
Q: The International Mother Language Day focuses on indigenous languages this year. What do you think AI could bring to indigenous languages?
VB: Most importantly, the promise not to be forgotten.
By some estimates, every two weeks a language dies with its last speaker, and between half to every 9th language is predicted to disappear by the end of the century.
If we catalogue the language somewhere, somehow, it will exist. There is a Russian saying which can be roughly translated as, “once words are written, they can’t be taken back” (in Russian, “чтонаписанопером, невырубишьтопором”). Today, with better tools, we can preserve context and samples, we can analyse its structure and derive conclusions about its origin and learn more about the culture that created it. Maybe even be used to decipher or understand another language, as MIT researcher Regina Barzilay demonstrated with Ugaritic in 2010 (http://news.mit.edu/2010/ugaritic-barzilay-0630).
A well-documented dead language may also come back to life. There are multiple examples of dead languages that were revived: Cornish, Dalmatian, Hebrew, and more.
As AI software today is an essential part of the modern infrastructure, the lack of software support causes native speakers to “abandon ship” and adds the risk of a language to become marginalised and eventually disappear. Monolingual speakers of poorly supported languages are somewhat locked outside the global discourse.
Sadly, the natural language processing today is mostly data-hungry, and therefore, it takes a lot of time for the advances to trickle down. We see it as our mission to change that.
Sentiment analysis, or opinion mining, is a process of finding out the sentiment expressed in a fragment of text. The idea is relatively young: first papers on sentiment analysis only appeared less than two decades ago (Turney, 2002). Its importance in various verticals coupled with the explosion in the volume of social media helped to fast-track the commercialization and the generous R&D investment.
Today, it is no longer enough just to answer whether the author of the content gives “thumbs up” or “thumbs down”. In this paper, we will lay the framework for more advanced applications of sentiment analysis.
World in Black & White: Classic Sentiment Analysis
The proverbial spherical cow in vacuum. Every bit as useful as the classic sentiment analysis
The document-level or classic sentiment analysis is meant to process a piece of text and answer the question, “is it positive, negative, or neutral?” The old naïve approach would just take every bit of negativity and every bit of positivity, sum them up, and calculate the score. Coupled with a bag of words method where the bits of positivity and bits of negativity were words or phrases (so-called “polarity terms”), the approach was hopelessly inaccurate. After a while, the approach was boosted with recognition of negations and other artefacts that modify the outcome. Then, the result was changed to a floating-point value.
However, none of that addressed the elephant in the room.
The concept of sentiment analysis was born out of the actual business need to predict whether the customer will buy the product or the service again, and whether they will recommend the members of their social circle to buy it. Straightforward logic, isn’t it? If they liked it, they will opt for the same vendor again given a chance.
Sort of.
In reality, the likelihood of people buying again is more than the mere sum of the grades given to different features. People don’t fly budget airlines because they like small legroom and dirty seats: they are trying to save money. They might put up with the poor service but they will flee at the first sign of pricing being no longer competitive. These customers will also not tolerate cancellations without refund and lost baggage, even if they are OK with the lack of inflight entertainment.
Already in the late 2000s, the online reviews became an established literary genre. They are often much longer than one sentence, and, most importantly, tell exactly what is good and what is not good. It’s all there! Unfortunately, the classic, “black & white” sentiment analysis was completely ignoring it, even with the “shades of grey”, that is, a floating-point score. Some sentiment analysis vendors went further and started assigning a score to every sentence. It did not solve the problem though, because one sentence may very well contain a number of factors in the customer’s decision.
While the simple “black and white” principle was easy to explain to the uninitiated business people holding the purse strings, the same business people needed better actionable intelligence. Why didn’t 67% of the guests like that hotel? If I have to go through these thousands of reviews manually to find this out, what exactly did your software accomplish?
Be More Specific: Aspect-based and Entity-based Sentiment Analysis
One figure could not provide an adequate response. There was a need to find out what exactly the reviewer liked and what they did not like. So-called aspect-based (or facet-based) sentiment analysis is meant to do exactly that.
Instead of determining sentiment for a document or a sentence, every relevant aspect encountered in the text is given a sentiment score. For example, if a review says, “the breakfast was a bit tasteless but I liked the helpfulness of the staff”, in the hospitality domain, the aspect “breakfast” would have negative sentiment while the aspect “staff” would have positive sentiment.
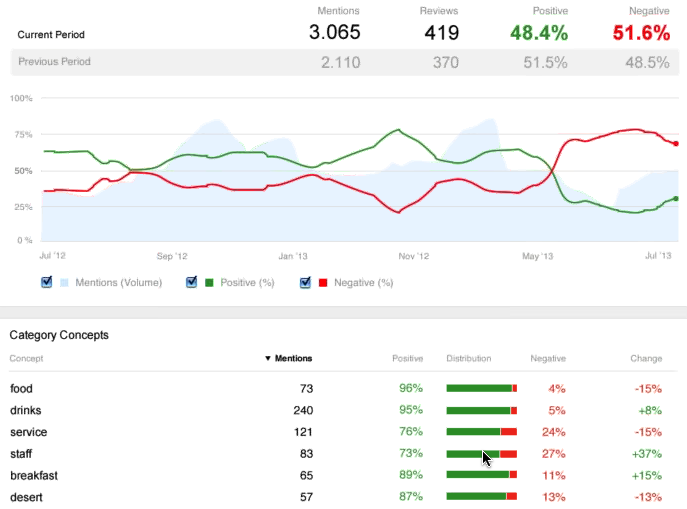
The aspects from different reviews can be then aggregated, drawing a big picture of customer preferences and issues. The screenshot below demonstrates such an application for the hospitality industry.
Sample front-end displaying the results of the aspect-based sentiment analysis
What happens if the review mentions several vendors or suppliers?
Then the sentiment must be determined for a specific named entity, e.g. a company. In a way, it is a variation of the aspect-based sentiment analysis, with the entities treated as “aspects”. However, there are two nuances.
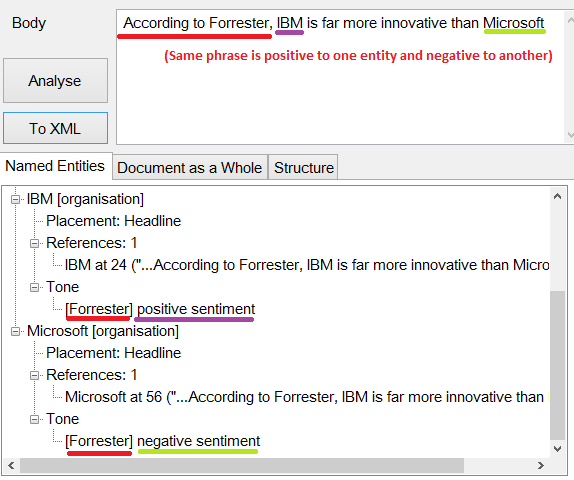
When two entities are compared to each other, the same clause may contain two sentiments. For example, “company X is more innovative than company Y” means positive sentiment for company X and at the same time negative sentiment for company Y.
While the regular aspect-based sentiment may contain a comparison between aspects, it doesn’t necessarily mean negative sentiment towards either (e.g. “I liked their breakfast more than their location” does not mean the location was bad and generally sounds contrived, while in case of the competing entities “less good” means “bad”).
The second nuance is that in both aspect-based and entity-based varieties of sentiment analysis, we may have cases where the sentiment is not generated by the author. Continuing the example above, “according to the analyst Z, company X is more innovative than company Y” does not bear direct sentiment. It merely quotes someone else. Depending on what the application is to accomplish, referenced sentiment may have to be ignored. This means that the sentiment analysis application must be able to detect quotations.
Sample entity-based sentiment analysis with opinion attribution
As the aspect-based and the entity-based sentiment analysis works with a collection of values, does it make sense to calculate an overall score giving different weights to different factors?
Clearly not in case of the entity-based variety: it doesn’t make sense to add the sentiment score of Orange S.A. to the sentiment score of Apple Inc.
What about the aspect-based sentiment analysis? We believe that it would still be a bad practice. Does the sentence “the room is small but OK” convey an overall positive sentiment? Maybe, but we should not discard the size aspect if the goal is providing actionable intelligence. Even if we disregard the complexity of coming up with the constituents that work well, different people may have different criteria for the product. Some don’t care about noisy environment in a hotel; others have to have convenient parking nearby that does not cost too much. Providing one figure may tempt the integrators and the aggregators to discard everything else, and the end-user will only get to see a questionable, one-size-fits-all score.
This is Not a Pipe: Sentiment Analysis of Creative Content
Aspect-based sentiment analysis seems to be providing an adequate solution for reviews of goods and services. A praise means positive sentiment; a message of disapproval means negative sentiment. This is not always the case when discussing movies or fiction in general.
“Realistically depicted bad guys” means that by common ethical standards, the characters in the movie would be judged negatively. However, we are not judging these fictional people; we are judging the work of art depicting them. This work of art gets points for realism, quality of acting, good plot, and so on. It does not get demerit points for unethical conduct of the characters it depicts or the dirty and unsafe streets of the imaginary city.
As difficult as aspect-based sentiment analysis is, sentiment analysis of creative content raises the bar even further. It is a sub-type of the aspect-based sentiment analysis, with the distinction that we have to ignore many of the aspects of the review. It’s not enough to merely take into consideration some aspects: a character doing something stupid in the movie can be ignored; a script writer who made a stupid decision, on the other hand, means negative sentiment.
René Magritte’s famous The Treachery of Images warns that a painting of a pipe is not a real pipe; and so the parts of the review describing the imaginary universe of the creative content being reviewed, are to be excluded from the sentiment analysis.
Let’s run a sample movie review through a regular aspect-based sentiment analysis:
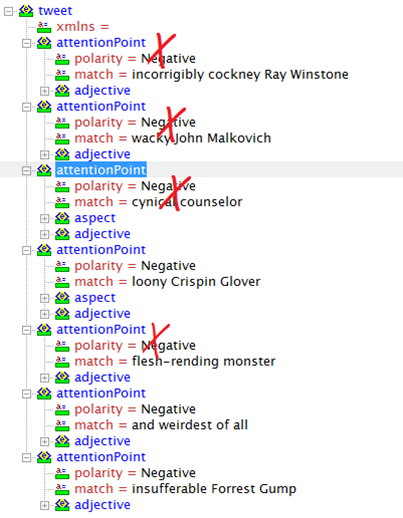
I didn’t expect a lot from ‘Beowulf’, for lots of reasons, most of which were to do with the casting: incorrigibly cockney Ray Winstone as a warrior from what’s now southern Sweden; wacky John Malkovich as a cynical counselor; loony Crispin Glover as a flesh-rending monster, and weirdest of all, Angelina Jolie as the monster’s mother… Then there was the way they did the whole thing in CGI, running the risk of making it all look a bit rubbery. Finally, Robert Zemeckis presided over the insufferable ‘Forrest Gump’.
While the straight aspect-based sentiment analysis did find the necessary snippets, it completely misses the point as demonstrated below:
Aspect-based sentiment analysis applied on the movie review
Being “incorrigible” or “wacky” may be a bad thing in the world of customer service. It is not necessarily bad for an actor. A character being cynical or a monster does not mean the reviewer did not like the movie; it just refers to the imaginary universe. On the other hand, “looking rubbery” may be neutral in customer service but negative when it comes to CGI.
However, once we ignore the imaginary universe, focusing only on specific aspects, it’s not much different from the generic aspect-based sentiment analysis. Fortunately, the tools of Tisane Labs allow configuring exactly what we want to capture, and the solution is to create a special configuration targeting only specific aspects.
Tell Me Who Your Friends Are: Sentiment Analysis for Politics
The sentiment analysis of political content is far more difficult than any other type and adds more moving parts to the equation. One part of this type of sentiment analysis is largely the same as any other aspect-based sentiment analysis: unethical conduct, inadequate skills, etc. are bad things; ethical conduct, being skilled are good things. Nothing special here — a regular entity-based sentiment analysis. The regular reservations about the entity-level sentiment analysis apply as well: the external allegations and quotations have to be eliminated from the result or returned within a sub-scope.
Things get more interesting, however, when the sentiment is expressed indirectly.
A comparison to, or allegations of an affiliation with a notorious dictator or a criminal is clearly a negative sentiment. However, these are all named entities; how do we know that being linked to a person X is a bad thing? Can’t we just assemble a list of all the bad guys and mark an association with them as a bad thing?
We can’t. These scapegoats may not be universal scapegoats. For example, Democrats in the United States may use prominent Republican figures as this kind of “locally negative” entities, and vice versa; any nation at war or in poor diplomatic relations perceives the other side negatively.
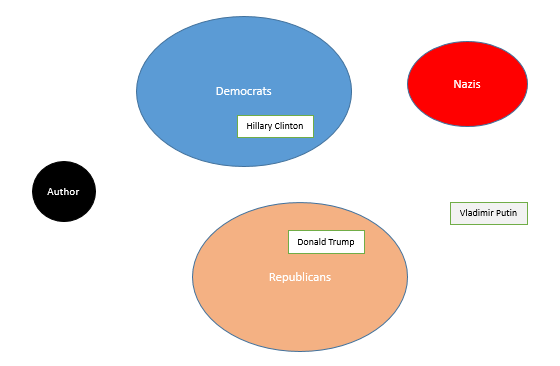
Heated discourse over the 2016 Presidential Elections in the US is a good example. For the sake of simplicity, let’s focus on the main entities as depicted on the diagram below:
Simplified diagram of main actors in the 2016 US Presidential election
Democrats with Hillary Clinton, and Republicans with Donald Trump. Let’s assume the author of a post does not give away his attitude by calling the Democratic candidate “Killary” or the Republican candidate “Drumpf”. If the author equates one of these politicians with the Nazis as a group (or, for that matter, any prominent member of the Nazi government, like Goebbels or Himmler), the sentiment is most likely negative (unless the author belongs to a small fringe group). It is less clear when the author alleges association with Vladimir Putin; it became clearly negative in the US as the election was closing but not universally damning earlier. Furthermore, it is not necessarily negative if uttered by commentators outside of the United States.
In other words, it’s all relative to the author of the content. Tell me who your friends are, and I will tell you whether the sentiment is positive or negative.
Considering that in most cases, these links are pointed out in a negative context (if it were positive, it would be known to everyone, and there is no need to point them out), it is tempting to assume that any association is negative. But that is not necessarily the case, as sometimes they are mentioned to demonstrate even-handedness or an affiliation with a friendly group.
This means that in order to resolve whether the association with a group or an actor within this group is mentioned in a positive context, the analysis needs to know where the author, or the group which the author is associated with (e.g. a news agency with a stable general political orientation), stands. Other than that, this aspect can only be returned as a relationship between entities, which may or may not bear sentiment polarity.
In practice, this means either returning a collection of “absolute” sentiment values with a collection of “relative” sentiment values, or working with a knowledge base of political groups to resolve the relative sentiment values.
Conclusion
Sentiment analysis is a young and dynamic area. As the social media is catching up with the traditional mass media in its importance, and have long exceeded it in volume, the importance of accurate and powerful textual analysis in different scenarios is difficult to overstate.
We believe that this critical review and suggestions in it will encourage productive discussions and yield new approaches. We are working to bring them to life at Tisane Labs. If you’re curious, do drop by and try out our take on the sentiment analysis 2.0.