Watch Your Language
As the cautionary tale of Parler shows, lack of proper moderation may bring down an entire community. All it takes is one incident that may raise the prospect of lawsuits or consumer campaigns to delete your app for everyone involved even indirectly. Nor is it the first time: back in 2018, Gab was forced offline over the Pittsburgh synagogue shooting.
It’s not just the United States. Virtually every jurisdiction today has laws to make sure that online chatter does not cause offline issues. You think you can host your controversial website in Russia? Think again. Roskomnadzor (a Russian federal service in charge of censorship of communications) goes beyond banning neo-Nazi outlets. For example, some websites are forced to replace specific Russian swearwords by “describing what they mean” instead, as in a charade. (Literally descriptions like, “a word made of four letters starting with X that rhymes with Y”.)
And if it weren’t for the threat of deplatforming, users leaving, and pressure from campaigns like Stop Hate for Profit, brands are no longer happy to let their ads be displayed near problematic content. When the №1 advertiser on Facebook considers pulling their spending, no deplatforming is needed to get the message across. With the bulk of social media subsisting on ads, whatcha gonna do when no one wants to advertise with you?
Parler Case Study
A class action suit is basically a courtroom equivalent of an angry mob with torches and pitchforks looking for targets. It does not matter if a party was just marginally involved; if it can be proven that it was involved at all, and can pay, it will likely be named an accomplice.
Suppose there was an incident or a chain of incidents in which people got killed and massive damage was inflicted. The action was planned on a platform built by a small unprofitable startup, hosted on a cloud maintained by a trillion dollar company, and distributed via app stores by other trillion dollar companies. Do you think the lawyers, whose compensation may be contingent on the settlement amount, will miss an opportunity to pick on the big guys? Neither do I.
The reaction of Apple, Google, and Amazon therefore should not be surprising. What’s surprising is that Parler wasn’t deplatformed earlier, given the number of warnings AWS sent (note the obfuscated F-word in the first post; apparently, that’s what the author felt was the worst part of the death threat). Just before the deplatforming, the data dump of Parler’s user content has been obtained, and is now doing circles in the digital forensic community.
Could Parler have survived? They had moderation in place; very loose, but it was there: no porn, no spam, no obscene nicknames. Some observers complained about the policy being inconsistent and arbitrary. For example, a user got banned for mocking Parler, even though it was never against the published rules.
Clearly, what they had in place wasn’t enough. When you are repeatedly told by your hosting company that you have potential law enforcement issues, you better do something about it. Were they paying attention? Variety and others posted conflicting accounts of the former CEO and the shareholders, mentioning discussions about the need to crack down on the darker parts of the gray zone. Whoever said what, it does sound like the subject was raised.
If that’s the case, they knew it was problematic; they were discussing ways to mitigate the issue. But it took too long.
The moral of the story is, don’t let an inconsistent and lacking moderation policy become a trainwreck in slow motion.
Element Case Study
Just around the time when Parler went offline, Google banned Element, a messaging app using a decentralized protocol, from its app store. This time, however, it was only Google, and the ban did not last long. According to the firsthand account of an Element team member in Hacker News:
- it was an extremely severe violation.
- after an explanation how Element and Matrix work, Google apologized and reinstated Element.
- most importantly, both Element and Matrix provide a robust toolset to moderate the Matrix communities.
And that was the end of the story.
The sophistication of Matrix.org moderation toolset is impressive, and should be regarded as a gold standard. The creators of Matrix seem to realize that decentralized != chaos. They have a concept of policy servers, and a component that provides portable moderation and, as they say, “impersonal” rules. Contrast it with the approach of “poop emoji in the comments not OK, death threats OK, but sometimes not, and sometimes we’ll just kick out people who troll us”.
Because proper moderation is, like proper law enforcement, consistent and impersonal.
Tisane API: Moderation Aid Done Differently
Here in Tisane Labs, we build automated tools to tag problematic textual content. Tisane API is not a panacea by any means, but we work hard to avoid the common pitfalls. Our starting point is the need, not what can be done quickly. Some of the capabilities of Tisane appeared an overkill at first, only to be requested later by the users.
Outlined below are the core design principles of Tisane.
Transparency and Granularity by Design
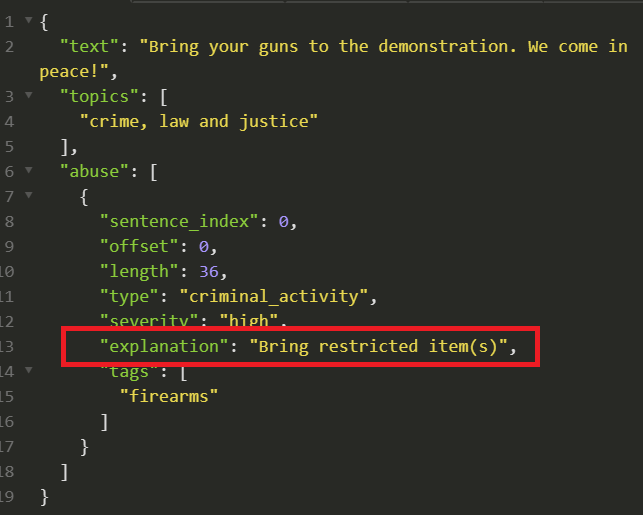
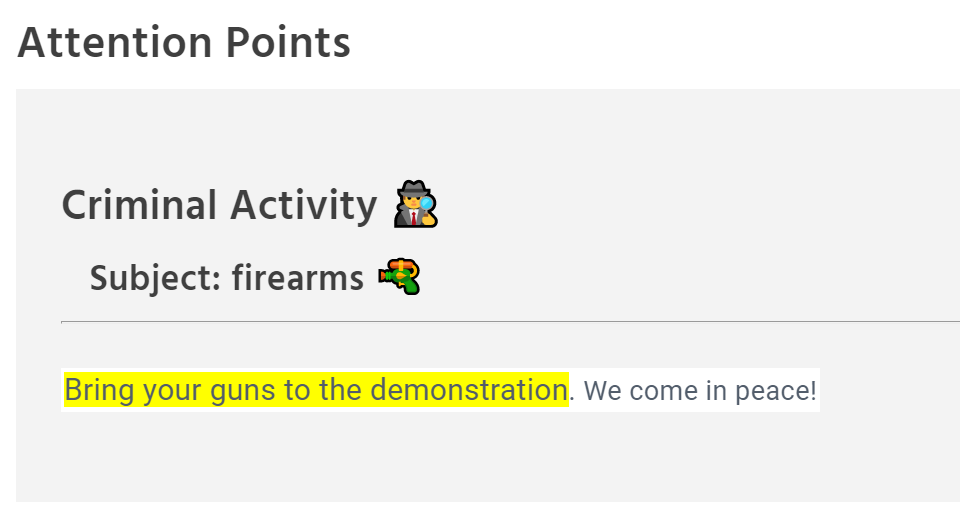
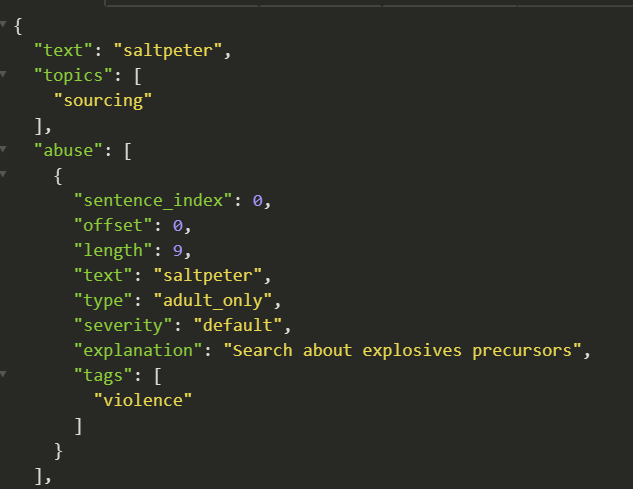
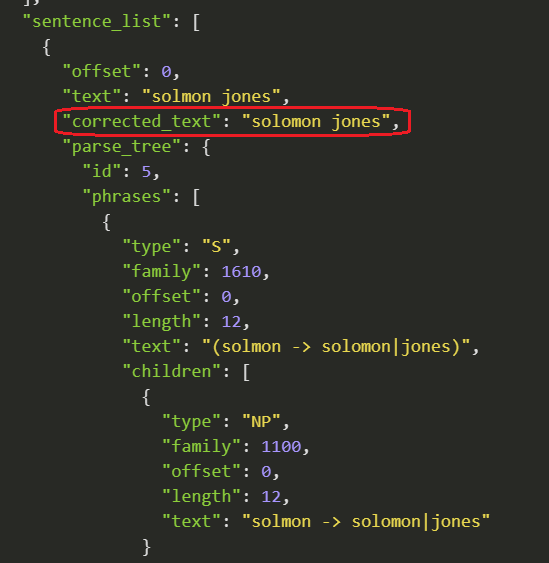
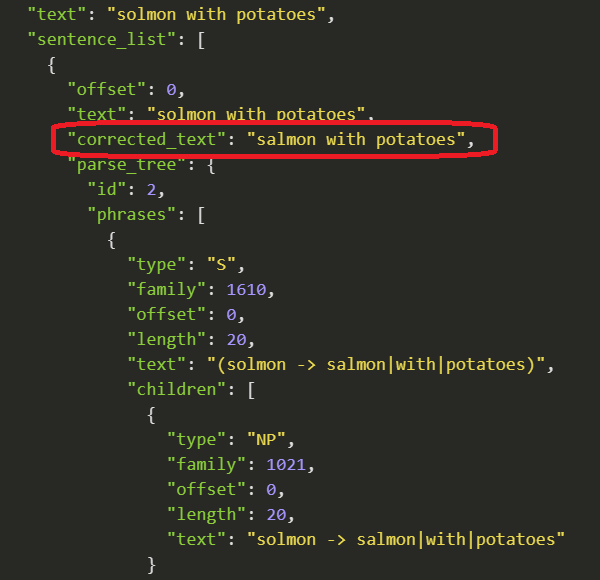
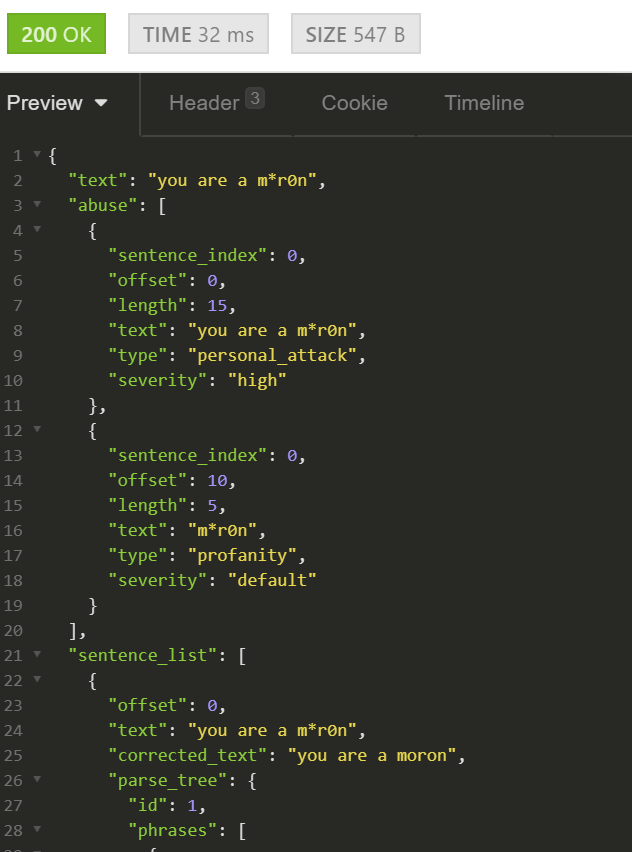
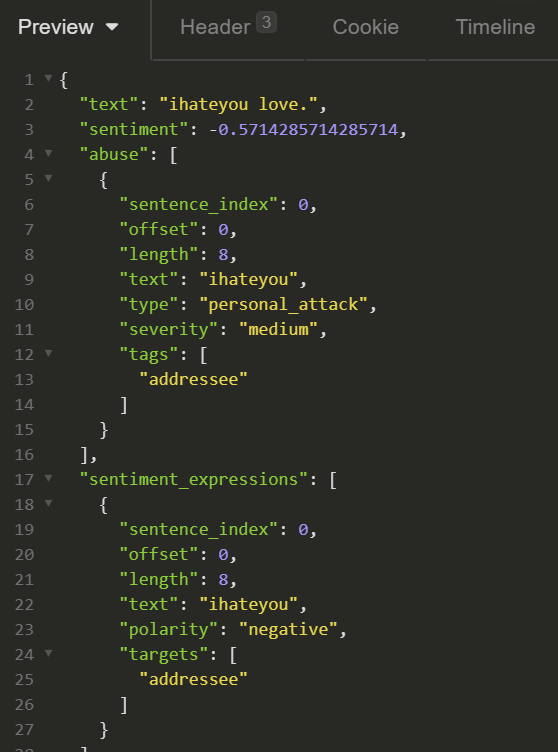
Every alert the system provides contains a built-in rationale, and the actual fragment that caused the alert.
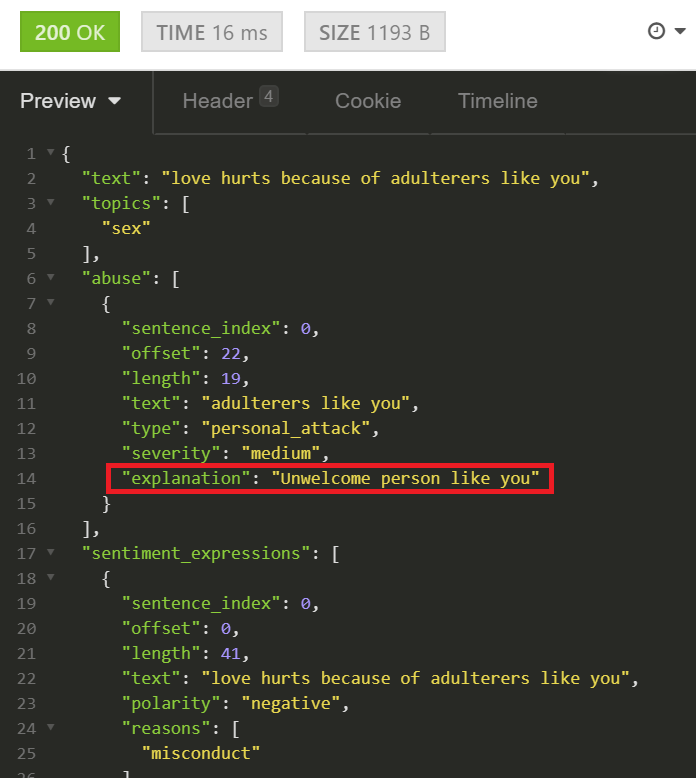
A moderator, with their human biases, likely overworked, underpaid, and possibly coming from a different culture, should not be required to be an arbiter and a professor on ethics. Nor should they be required to figure out what’s wrong with an non-abusive utterance like “I am a black sex worker”.
With Tisane, their task is reduced to verifying that the system interpreted the utterance correctly.
Consistent Decisions
Wouldn’t it be more democratic if every policeman could apply the laws the way they see fit? After all, they know the reality better than some lawmakers far away, right?..
Shocked? An insane idea, isn’t it?
And yet that’s roughly how many automatic moderation systems function today. Some rely on models trained by underpaid human annotators; others make it even worse and let the model be trained by decisions of moderators.
Do you want to get deplatformed because five of ten of your moderators were fixated on the poop emoji and taught the system to dismiss the death threats to public figures?
Tisane’s alerts are strictly aligned with the provided guidelines. Our built-in guidelines rely on principles today regarded as universal or near-universal. We do not tag content critical of a political faction or a public figure (unless they are part of the conversation) as a violation. We avoid political decisions; the management team of Tisane Labs, as well the rest of staff is made of people with very different opinions, mindsets, and backgrounds.
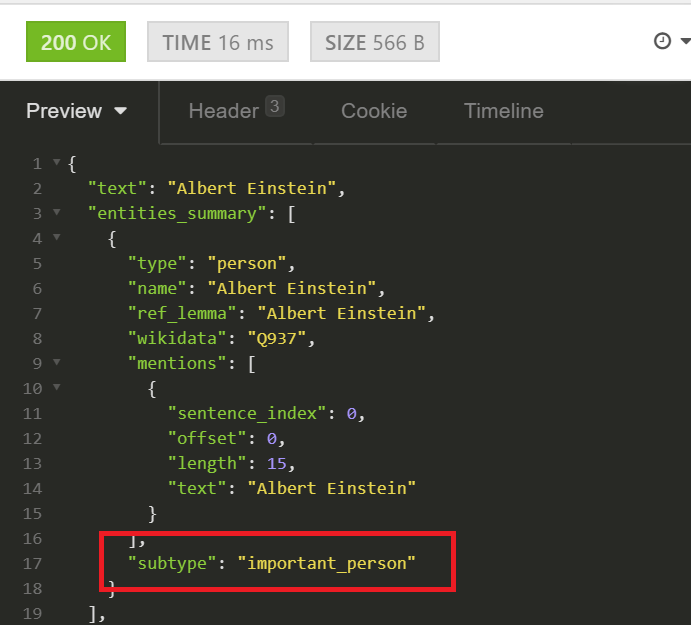
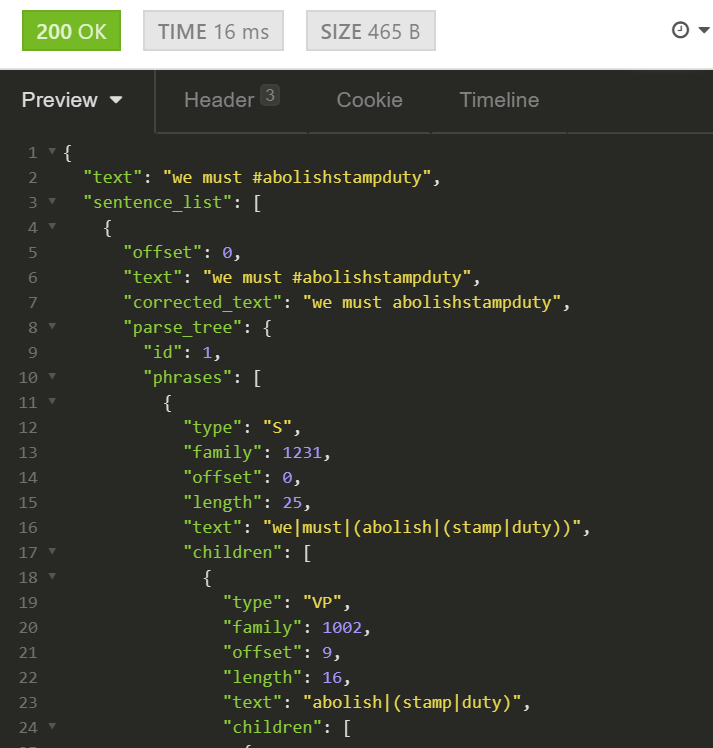
That said, if your community wants to steer clear of a particular topic (like the Peloton communities avoiding political discussions), there is a topic detection and entity extraction mechanism. Rather than providing a simple classifier, we follow the “Swiss army knife” approach.
Simplicity
We avoid floating point “confidence thresholds”.
It may give the developers a false sense of control, but it doesn’t make the decisions more accurate, let alone transparent. We view it as an equivalent of security theater in the airports.
Privacy and Data Security: On-prem
Sometimes, the conversations in the community may be more discreet. Whatever the policies of the vendor are, whatever jurisdictions they must be compliant with, some communities want to be shielded from changes in the legislation or intrusion into privacy. On the other hand, some communities have specific requirements, and need to construct their own guidelines.
Which is why Tisane has an option for an on-prem single tenant installation, with the ability to adhere to custom policies. Contact us to request more information.
Pricing
Moderation is important, but investing in fences and locks more than the house is worth makes no sense. We realize that moderation is akin to insurance policy, and keep our prices affordable.
To try Tisane, sign up here. The free plan does not expire.
Conclusion
Moderation is no longer a luxury. Even in cases when it’s not a legal requirement, running an online community without a moderation solution in place is akin to driving without insurance or never locking your house.
You may get away with it for a while, but as your community grows, the probability that bad actors abuse your platform is too high to ignore.