
Tisane has been around for half a decade. It stands apart from other text moderation tools with its architecture. We were shy about our unorthodox approach in our early years; now we have enough traction and confidence to come out.
Bird’s-eye View
Today, most text moderation APIs are either machine learning classifiers or rule-based engines looking for keywords. Tisane is neither.
Under the hood, Tisane is a sense disambiguation platform. It receives text as its input, and produces a knowledge graph. The nodes of the knowledge graph contain word senses rather than words; that is, a combination of a lexical item and its interpretation in the current context.
Then, labels are generated based on the combination of graph node constraints. These labels can be anything: entity types, sentiment values, or alerts about problematic content. Think of it as spaCy-like multipurpose engine, but based on a monolithic, interpretable architecture.
But Why?
tl;dr Because the mainstream solutions are broken in too many ways to count.
The simple keyword or blocklist-based solutions (aka clbuttic) may work for simple tasks in low-traffic communities but will make managing anything bigger or more complex a living hell. (Embrace your inner adolescent and read more with examples.) Most importantly, the bulk of issues do not involve “bad words” but “bad combinations” of neutral words.
Which is why machine learning solutions took over in late 2010s, with the promise of a more nuanced and context-aware solution. While the new paradigm did provide new ways of catching unwanted content, it also created additional issues. Perhaps, the biggest one is adding to the exponentially growing antagonism toward social networks. With the approach often falling back to a bag of words, utterances like “I am a black sex worker” may be perceived as racist. Tweaking and balancing would improve the accuracy somewhat, but not the trust of users whose messages were blacklisted with no explanation.

It is expensive and difficult enough to develop ML classifiers for the major languages. But the trickle-down economics for languages with less data worked even worse. Suffice to say that even juggernauts like Facebook did not deploy a classifier for a language with as many speakers as Hindi as late as in 2021.
But that’s not all.
Transparency, Transparency, Transparency
Just a few days ago the former Google Safety Lead, Arjun Narayan, named the black box aspect of AI one of its biggest issues. It’s hardly new or controversial. When in late 2022 Silicon Valley investor Sriram Krishnan spoke about his transparent moderation proposal, Mark Cuban countered that the roadblock is AI being black box and “hard to audit”:
Opaqueness, as we know, is baked in machine learning. The best explanation ML can give is pinpointing the nodes that influenced its decision. The rest is untraceable, a bajillion-dimensioned matrix multiplied by another bajillion-dimensioned matrix.
73% Likelihood of Naughty
If Kafka were writing his Der Process today, he would absolutely feature an equivalent of confidence values. Because being judged by a black box is not scary enough. It has to be a combination of a black box and dice.
The whole idea of pigeonholing human behavior into “naughty” and “nice” may be suitable for Santa Claus, but trust & safety people need to do better than that. And only a sadist Santa Claus would combine his own judgement with a roll of a dice. “Well, it’s 73% confidence value… yeah, probably naughty. If it were 72.98%, then the elves from Mechanical Turk had to take another look.”
We saw customers who hinge their entire moderation process on the confidence values; with both their classifiers and human moderators tending to err on the side of “guilty” (as a character in another Kafka’s story would put it, “guilt is never to be doubted”), the posters had to adapt their habits in a textbook example of leaky abstraction. They would obfuscate words like “fascist”, follow up with puzzled posts asking why they were banned after pointing out racism, and get banned again.
Industry leaders like Grindr’s Alice Goguen Hunsberger say that it’s not uncommon for an ML model to have high confidence but be wrong, and the human moderators must not be swayed by it.
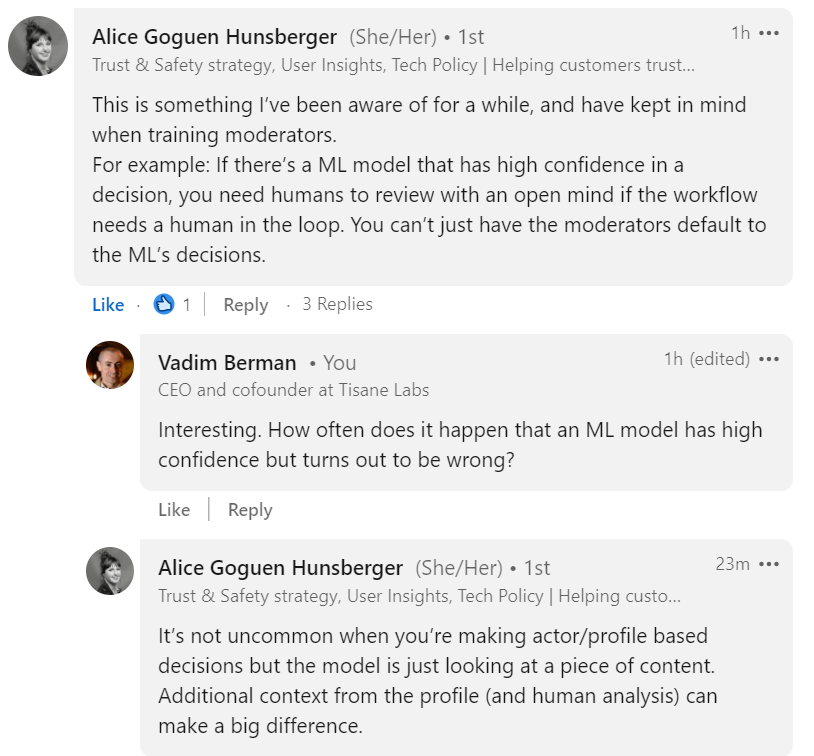
That sounds like (pardon the pun) a lack of confidence in confidence values to me, and Alice is far from being alone in it.
The confidence value is then a security theater, introducing dangers like automation bias. In the perfect world, human moderators are PhDs in ethics debating big philosophical questions; in the real world, they are underpaid students strongly encouraged to perform their tasks as fast as possible. “Computer says no” more often than not means the human moderators will say no, too.
Not a Nail, Abandon Hammer
Clearly, finding arbitrarily defined “nasties” in text is more than just a “classification task”. A proper platform used to punish and ban people needs to have the decency to explain itself. It needs to adapt to the ever-changing and ever-expanding needs. It needs to make do with little to no training data. And it needs to be serviceable and updateable without the need to retrain huge models, wasting resources and risking regressions.
In other words, a black box paradigm is a poor fit for text moderation engines. Not to mention that the logic of a giant switch case statement is a bad fit for curve fitting in general.
Yes, trust & safety people found ways to adapt to the deficiencies of the current black box engines. But look around you. The discontent is everywhere, regardless of the political and social views. And even top tier communities like Twitter still fall back to keyword-based decision flow. Laws are being drafted to change the situation and right the perceived wrongs. World authorities in trust & safety talk about the tools being inadequate for their needs. While the objections target the process in general, the shaky technological base is at the heart of the issue.
What is Tisane, Anyway?
“You say ML is a bad fit and keywords are inadequate. What did you build then?”
Tisane is a knowledge graph solution, but much more granular than most its peers. Architecturally, it can be viewed as a symbolic counterpart of seq2seq. Our language models contain a rich set of morphological, syntactic, and semantic features, merged from a variety of sources. Because the runtime is symbolic and interpretable, we have full control over the flow, and can introduce new device at any stage.
Of course, building this kind of engine together with proprietary language models for it is easier said that done. If you’re a bit older, you may be familiar with mostly aborted attempts to build this kind of a multipurpose contraptions. As anyone familiar with this architecture will tell you, it’s basically a hoop-jumping marathon with contestants dropping like flies. What only 5% of those who tried building it will tell you is that once you’re done with the Shawshank Redemption-style sewer crawl, things become much easier, and adding new features that take ages with other engines gets trivial.
So what did we get with our off-the-beaten-track approach?
Algorithmic Transparency
The primary requirements are:
- highlight the actual issue
- tell why you think it’s an issue
Tisane both pinpoints the problematic fragment and, optionally, provides a human-readable explanation why it thinks the fragment is problematic.
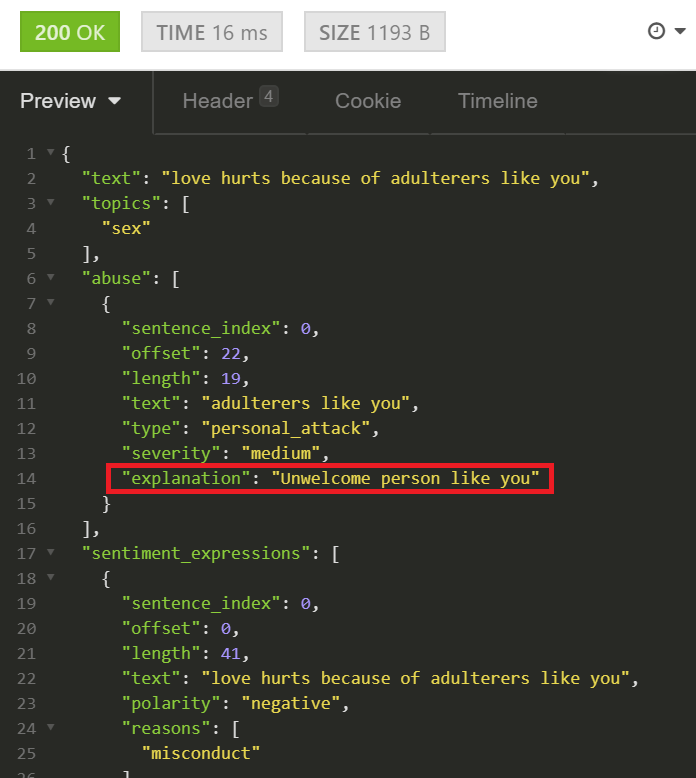
How is it possible? Much like other parts of the language building process, Tisane design workflow utilizes a combination of automated techniques and expert input with a highly efficient formalism. (The runtime is symbolic, but the designer platform is a literal smorgasbord!) In the example above, the “unwelcome person” may be any kind of unwelcome person, be it “liar”, “cheater”, “thief”, “coward”, etc. The query is on the specific nodes in the parse tree; meaning, it can also be interspersed with stray nouns, adverbs, and more (assuming the sentence is making grammatical sense or close to it, of course). The queries are across languages; as one such query covers thousands of combinations in one language, multiply it by the number of supported languages for the total coverage. Queries can be quite specific and convoluted, like tweezers for data extraction.
With Tisane, a human moderator does not need to scan a huge wall of text and scratch their head trying to figure out why “computer says no”. Tisane provides the reasoning behind its decisions, according to the requirements of EU Digital Services Act and other frameworks. The moderator job then is reduced to a sanity check, rather than trying to figure out alien logic while acting as a judge and an executioner. If Tisane messed up, it’s not going to cover its tracks; it’ll make it obvious.
If it isn’t enough, and the language model designer wants to drill down into the parsing process, there is a special web-based debugger which replays the process step by step and generates debugging info for the structures involved.
Flexibility and Maintenance: Not Like a Box of Chocolates
It is well known that 60% of software life cycle costs come from maintenance. With the black box ML engines, the need to retrain the entire model every time pushes the costs even higher. Retraining a model in an attempt to eliminate a flaw may introduce regressions, with the consistency difficult or even impossible to control. A bit like the Forrest Gump’s box of chocolates, but of the kind nobody wants.
In contrast, Tisane’s processing flow is predictable. That is not to say that regressions are impossible; it is software, after all. But all conflicts can be tracked and ultimately resolved. Generating a language model from the design tables (“compilation”, as we call it) takes minutes on a very standard machine without GPUs (or seconds for the metadata).
Granularity
When everything is structured, adding more features to the word sense nodes becomes trivial. For example, with hate speech, most engines already moved to tag that it’s hate speech (rather than a generic “toxicity” label from mid-2010s). Tisane takes it one step further and also adds the sub-type of bigotry (e.g. Islamophobia, homophobia, xenophobia, etc.).
How did it come into being? A customer asked whether it’s possible, and it took a couple of hours to map the root nodes; the rest was propagated automatically.
The requirements multiply faster than anyone expects, and so new features are not added just for the heck of it. We don’t have to build a new model every time, just add a couple of features to the model.
Cloud Providers Hate Him
Over its analysis, Tisane plays numerous what-ifs and is far more resource intensive than a simple syntactic parser or a part of speech tagger; in fact, these tasks are included in the analysis process. But it doesn’t come close to the CPU and RAM consumption of machine learning moderation engines.
Tisane runtime is built on cross-platform POSIX C++, with native editions for Linux, Windows, and maybe other OSes in the future. It is small enough to be deployed on device, and some of our customers do just that.
Last but not least, Tisane is an energy efficient C++ application, with C++ consistently rated as one of the most energy efficient programming languages. And while it may be disappointing for AWS, Azure, and Nvidia, we know that we contribute way fewer carbon emissions than our energy-hungry peers, and save a lot of hosting expenses for our on-prem customers and ourselves.
Language Trickle-Down Economics
Tisane’s language model design module is built to combine input from different sources: fuzzy matching, guided import, and manual expert input. (Plus generative AI, see closer to the end.) While we can use them for benchmarking, we do not require tagged datasets to learn from; we may utilize sources like Wikidata (as a starting point), augmenting them with expert input in more ambiguous cases.
This opens vast opportunities when tackling niche and low-data languages. A training set does not have to come in one package or (again) a black box. We don’t have to wait decades until enough data “trickles down”.
Multistep Detection
While for most trust & safety tasks the logic can be found in one sentence, or maybe in another one just before it, some cases are more complex.
Consider the following utterance: “Where are your parents now?” On its own, we don’t have enough context to mark it as problematic. It can be anything: two kids talking about their parents or a repairman trying to locate the head of the household. Then consider another utterance: “Can you turn on your camera?” Once again, the utterance alone does not necessarily imply nefarious intent. It may be from a conversation between colleagues at work. However, when the request to turn on the camera follows the inquiry about the location of the parents, it makes a lot of sense to issue an alert.

Tisane makes use of flags that can be set externally or internally to accumulate pieces of evidence when several signals are required.
Specific Context: Treachery of Games

The same flag mechanism also helps to reduce false positives. For example, in gaming chats, or chats discussing competitions, “Shoot him!” or “We’re gonna kick your a*” are perfectly acceptable and are not indicators of ill intent.
Tisane has a special flag to prevent “competitive language” from triggering alerts, and a mechanism to parse coded language.
Future Proof
When ChatGPT made everyone pay attention to generative AI, we were taken aback like many others, and even worried. But that didn’t last long.
The separation into the design platform and the runtime allows plugging whatever future technologies may emerge into the design platform, which still produces the same format, but with more accurate extraction and more new features.
For example, we’re using generative AI to suggest changes to our knowledge graphs and correct anomalies.
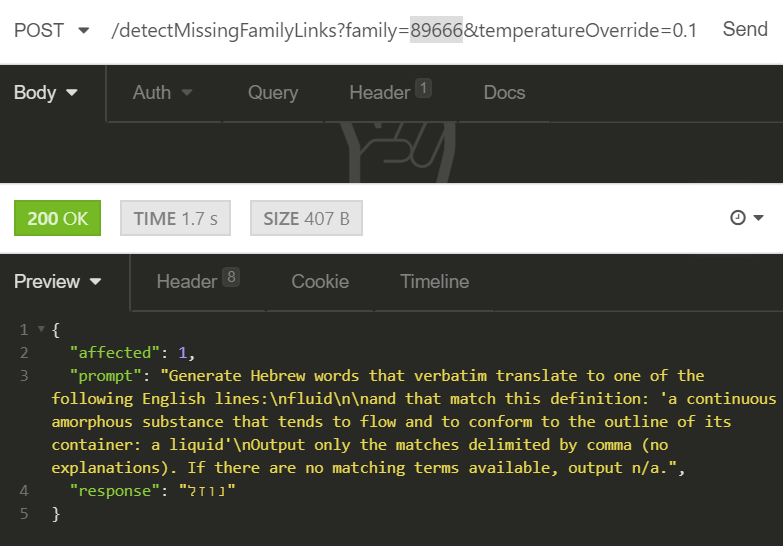
In a way, we’re creating a combination of an “LLM snapshot” and manual adjustments, while enjoying the best of both worlds: deterministic, efficient Tisane and coverage of edge cases that the original Tisane language models may have been lacking. It is also possible that Tisane can be used as a “Trojan horse” to get some generative AI functionality to the enterprise.
Conclusion
We’re no longer asked whether this kind of architecture is viable, or whether it’s more fragile. We have proven it’s viable, robust, and, most importantly, solves nagging issues that other paradigms don’t.
Can a traversable deterministic graph of entities offer unique advantages beyond trust & safety? Tisane is already actively used in law enforcement and national security, where determinism, explainability, and data economics are essential. We are open to other future applications, too.
Have any questions or comments about the topic discussed in this post? Feel free to comment or contact us and we’ll be happy to help!